Anthropicが、新フロンティアモデル「Claude Mythos Preview」を発表。
でも、あまりにも高性能すぎで、このモデルは一般公開は見送り。サイバーセキュリティ上のリスクが高すぎるとAnthropicが判断したため。ですが、同社はすぐにApple・Microsoft・Googleら12社と共同で防衛目的に限定した活用イニシアティブ「Project Glasswing」を立ち上げました。

Claude Mythos、Project Glasswing立ち上げまでのポイントまとめ
- Claude Mythos Previewは全主要OS・全主要ブラウザにゼロデイ脆弱性を発見できるレベルの能力を持つ
- 能力が高すぎるとして一般公開を見送り、防衛目的のみに限定提供
- Apple・AWS・Microsoft・Google・Cisco・NVIDIA・CrowdStrike・Palo Alto Networks・JPMorganChase・Broadcom・Linux Foundationが参加
- Anthropicは参加組織に1億ドル分の使用クレジットを提供、オープンソース団体へ400万ドルを寄付
- 90日以内に発見した脆弱性と成果を公開レポートとして発表予定
- 将来的には一般向けClaude Opusモデルにセーフガードを統合したうえで段階的な展開を目指す
Claude Mythos Previewとは何か
Claude Mythos Previewは、コーディングと推論において現行モデルを大きく上回る能力を持つ未公開のフロンティアモデルです。
Anthropicはこのモデルを使って、数週間のうちに主要なOSやブラウザを含む重要ソフトウェアにおいて数千件のゼロデイ脆弱性を発見したと報告。その一部はすでにパッチが適用されており、具体的な例として以下が挙げられています。
- OpenBSDの27年前から存在した脆弱性——接続するだけで遠隔からクラッシュさせられる欠陥
- FFmpegの16年前の脆弱性——自動テストが500万回実行されても検出されなかったコードの欠陥
- Linuxカーネルの複数脆弱性の連鎖——一般ユーザー権限からマシンの完全制御を奪取可能にする攻撃チェーン
なお、これらの脆弱性はすでに各ソフトウェアのメンテナーに報告され、修正済みとなっています。
Mythos Preview vs Claude Opus 4.6:ベンチマーク比較
Anthropicが公開したベンチマークでは、Mythos PreviewはClaude Opus 4.6を全項目で大きく上回っています。
BENCHMARK
| 項目 | Mythos Preview | Opus 4.6 |
|---|---|---|
| CyberGym(脆弱性再現) | 83.1% | 66.6% |
| SWE-bench Verified | 93.9% | 80.8% |
| SWE-bench Pro | 77.8% | 53.4% |
| GPQA Diamond(推論) | 94.6% | 91.3% |
| Humanity’s Last Exam(ツールあり) | 64.7% | 53.1% |
なぜ一般公開しないのか
Anthropicによれば、Mythos Previewが持つ能力は「防衛者にとって有益である一方、悪意ある攻撃者が同様の能力を手にした場合の被害が甚大になる」と判断したため、一般ユーザーの公開は行われていません。
同社はステイトメントの中で、「AIモデルはすでに、最も優秀な人間のセキュリティ専門家を除くすべてを上回る水準でソフトウェアの脆弱性を発見・悪用できる段階に達している」と述べています。
この状況に対応するためにAnthoropicは「Project Glasswing」を立ち上げました。
防衛側が先手を打てるよう、信頼できるパートナー企業に限定してモデルへのアクセスとクレジットを提供し、その知見を業界全体に還元する設計になっています。
PROJECT GLASSWING
- 参加企業:AWS・Apple・Broadcom・Cisco・CrowdStrike・Google・JPMorganChase・Linux Foundation・Microsoft・NVIDIA・Palo Alto Networks(計12組織)
- Anthropic提供クレジット:1億ドル相当
- オープンソース団体への寄付:400万ドル(Alpha-Omega・OpenSSF・Apache Software Foundation)
- 追加アクセス提供:40以上の重要インフラ関連組織
- 一般提供時の価格:入力$25・出力$125(per million tokens)
- 公開レポート:90日以内に発表予定
💬 軽めインプレ所感
僕もClaudeでSKILL.mdのアップデートに勤しんでいるので、次のモデルは楽しみでした。でも、まあ現状のモデルでも十分優秀ですよね。プロンプトが曖昧でなければ、レスポンスはそこそこの精度。たまにコンテキストが多くなるとエラー出すけど、それは使い方の問題でもあります。
なので、さらに高性能なモデルを防衛対策を施さずに、誰でもアクセスできるようになると社会レベルでデメリットが大きい、という判断もわかるし、主要テックメーカー・オープンソース団体に優先的にアクセスしてもらって、防御セキュリティ対策の一環としてMythos Previewを提供する、というのは最良の方向かと思います。
ちなみにベンチマークにあるように、純粋な推論・理解力を測る、大学院レベルの専門知識を問う問題集「GPQA Diamond(Graduate-Level Google-Proof Q&A)」の値はMythos Previewが94.6%。Claude Opus 4.6が91.3%。
この二つのモデルでは、そんなに大きな数字では無い、ということからも今のOpus 4.6の推論レベルの高さがわかります。
「Google-Proof」というのは検索しても答えが出てこない設計。”Diamond” は難易度の高いサブセットを指すティア名で、最難関の問題群となっていて、ヒューマン(非専門家)の正答率が約65%、専門家でも約74%とされていて、Mythos PreviewもOpus 4.6も正答率は大きく上回っています。
なお、現在のトップはGemini 3.1 Proで94.3%。
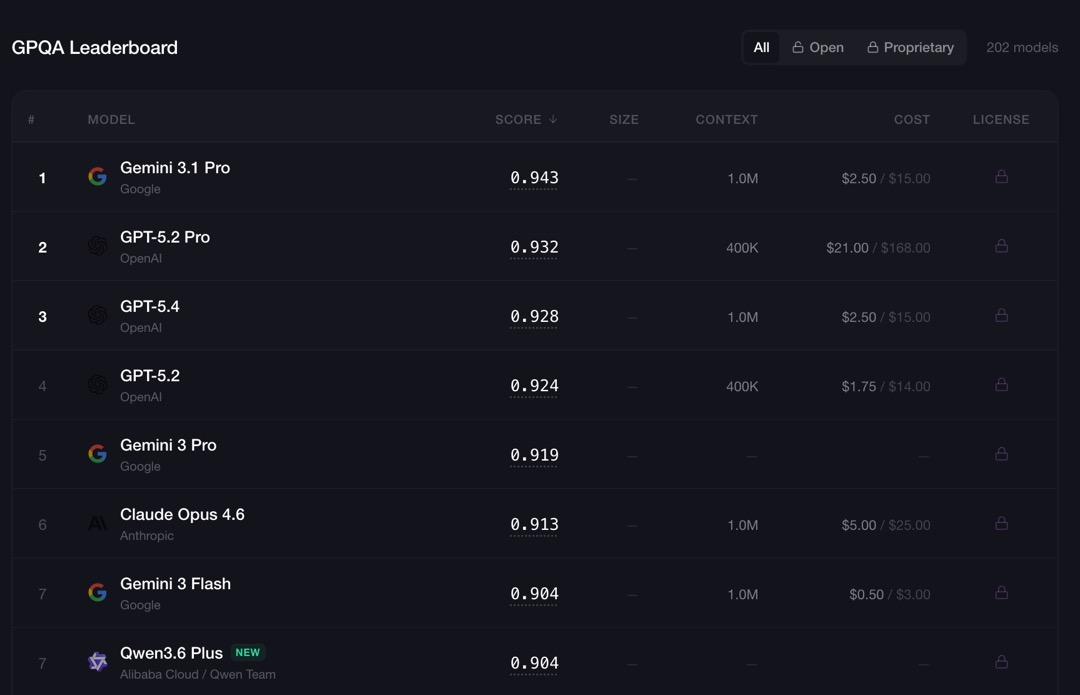
94.6%のMythos Previewがリリースされると、僅差で一位か。
とはいえ、もう、このレベルは専門職でもない人が性能差を判別することはできないと思うけど。